We demonstrate a world model for the full suite of policy evaluation applications in robotics: from in-distribution evaluations, to out-of-distribution generalization, to safety.
Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
Overview. We present a generative evaluation system built upon a frontier video
foundation model (Veo). The base video model is fine-tuned to support robot action conditioning and
multi-view video generation, while integrating generative image-editing and multi-view completion to
synthesize realistic variations of real-world scenes along multiple axes of generalization.
Action Conditioning
Multi-view generation
Action Conditioning. We finetune the pretrained Veo model on a large-scale robotics dataset consisting of diverse tasks that cover a broad range of manipulation skills across a multitude of scenes. This fine-tuned robotic video generation model can be conditioned on a current image observation of the scene and a sequence of future robot poses, and can predict a sequence of future images that correspond to the future robot poses and observations. The video above shows an example of rendered poses overlaid over the video generated using these poses as conditioning.
Multi-view generation. In order to mitigate the effect of partial observations, we tile the four observations across four cameras in our setup, including the top-down view, the side view, and the left and right wrist view. We finetune Veo to generate the tiled future frames conditioned on the pose images described above. The video below shows an example of multi-view generation.
We perform 1600+ real-world evaluations with eight generalist policy checkpoints and five tasks in order to demonstrate the following capabilities: (i) accurate prediction of relative performance and rankings of robot policies in pick-and-place tasks that are within the domain of the system’s training data, (ii) accurate prediction of the relative degradation caused by different axes of OOD generalization (objects, visual background, distractors) for a given policy, and also accurate prediction of the relative performance of different checkpoints, (iii) predictive red teaming for safety: by rolling out policies in edited scenes that involve safety-critical elements, we can discover potential vulnerabilities without hardware evaluations.
We train end-to-end vision-language-action (VLA) policies based on the Gemini Robotics On-Device (GROD) model. We then use the fine-tuned Veo (Robotics) model for evaluating policies in nominal (i.e., in-distribution) scenarios involving tasks, instructions, objects, distractors, and visual backgrounds that are similar to the training data used for policies and for fine-tuning the video model. Videos below show examples of video rollouts alongside real-world executions.
We compare predictions made by Veo (Robotics) for 8 VLA policy checkpoints with real-world evaluations. The videos below show examples of Veo (Robotics) rollouts for two policies.
Strong policy
Weak policy
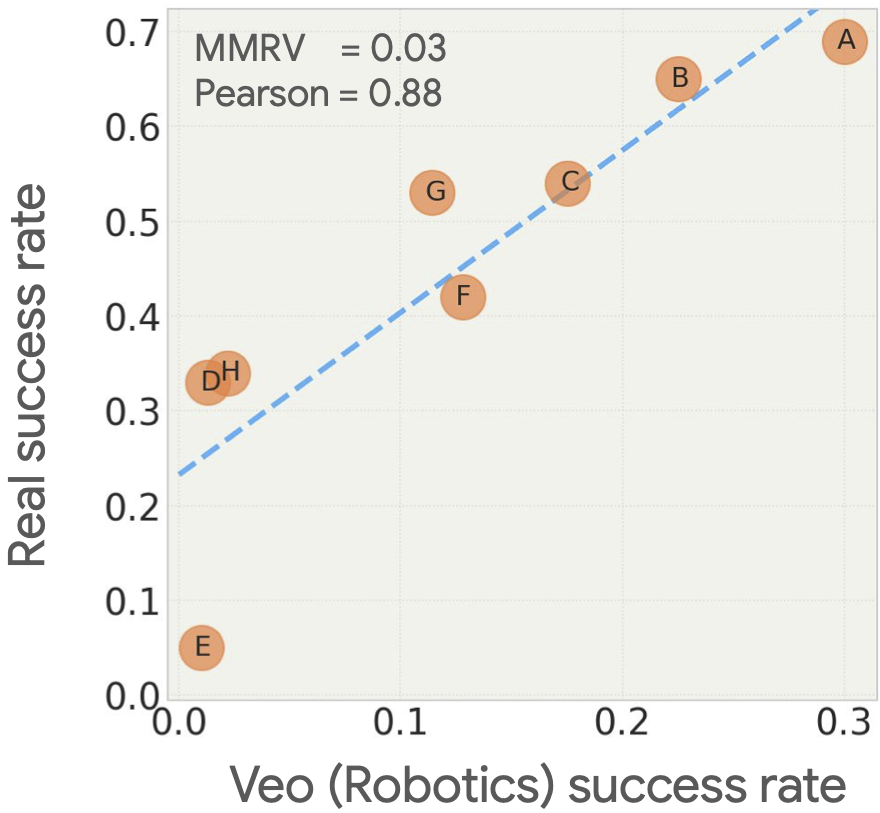
The plot below compares predictions from video rollouts with real-world success rates. We observe that Veo (Robotics) is able to rank the different policies by their performance. We also observe a strong correlation between predicted and actual success rates.
We utilize generative image editing to create realistic and diverse variations of real-world scenes for probing OOD generalization. The videos below show examples of Veo (Robotics) rollouts alongside real-world executions in OOD scenarios.
Polar bear distractor
Dog distractor
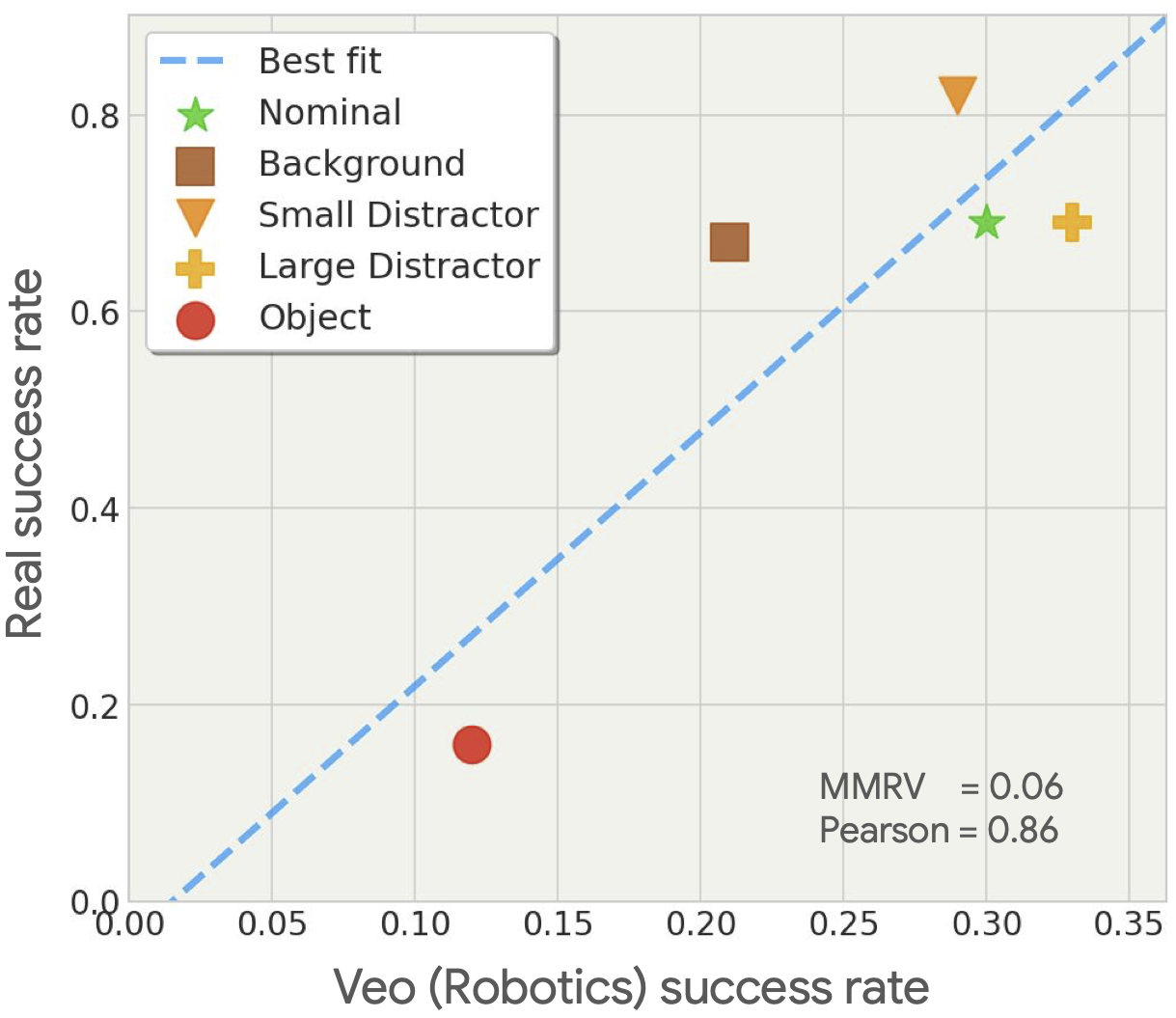
The plot below compares predicted success rates for different OOD conditions with real-world success rates (for a particular policy). We observe that our evaluation method is able to rank the conditions by their impact on performance. We also observe a strong correlation between predicted and actual success rates.
We demonstrate that the Veo (Robotics) world model allows us to perform red teaming for safety. The videos below show examples of potentially unsafe behaviors found using the world model, and corresponding real-world experiments conducted using props.
We are still in the early days of video modeling for robotics. The videos below demonstrate a number of challenges that remain to be addressed, including improved multi-view consistency and more realistic physical interactions.
Multi-view inconsistency
Object appearing
Object duplication
Unrealistic physical interaction
@misc{veorobotics2025,
title={Evaluating Gemini Robotics Policies in a Veo World Simulator},
author={Gemini Robotics Team and Krzysztof Choromanski and Coline Devin and Yilun Du and Debidatta Dwibedi and Ruiqi Gao and Abhishek Jindal and Thomas Kipf and Sean Kirmani and Isabel Leal and Fangchen Liu and Anirudha Majumdar and Andrew Marmon and Carolina Parada and Yulia Rubanova and Dhruv Shah and Vikas Sindhwani and Jie Tan and Fei Xia and Ted Xiao and Sherry Yang and Wenhao Yu and Allan Zhou},
year={2025},
eprint={2512.10675},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2512.10675},
}